
Field notebooks and diaries have historically been retained by natural history institutions as reference files for museum specimen and associated collecting events. More recently, however, researchers have begun to uncover vast historical data sets as part of their scholarship in scientific taxonomy, species distribution and occurrences, climate change studies, and history of science. Field notebooks contain significant information related to scientific discovery and are rich sources for data that describes biodiversity across space and time. They enhance our understanding of field expeditions by narrating meteorological events, documenting personal observations and emotional perspectives, illustrating habitats and specimen, and recording dates and locations. Unfortunately much of this information is almost totally inaccessible. Even digitized collections require users to sift through hundreds or thousands of images and take highly detailed notes to extract their content.
Enter (hopefully) Citizen Scientists!
By crowdsourcing the collection of this information and parsing it into sets of structured data, BHL users will be able to engage in qualitative analyses of scientists’ narratives as well as quantitative research across ranges of dates and geographical regions. Full text transcriptions will allow us to index and provide keyword searching to collections, and pulling facets out of this unstructured data will help make the access more meaningful and useable.The ultimate goal is for BHL to integrate taxon names, geographic locations, dates, scientists, and other types of observation and identification information with the published and manuscript items across BHL. By attaching this historical metadata to catalog records of published literature and archival collections, BHL will be able to provide a more complete picture of a given ecosystem at a given time.
To this end one of my first tasks when I arrived at MCZ was to familiarize myself with the current landscape of tools for building crowdsourcing, citizen science, and manuscript transcription projects. While there are several successful designs and models, in order to focus my scope I concentrated on those that met the following criteria:
- Built or updated within the last three years. Granted there are some important lessons to be learned from some of the older projects, but I need some current references.
- Use tools that are free or open source. BHL is committed to providing open access to biodiversity literature, and a good way to honor that is to focus on projects that share similar values. Also, we’re a bunch of libraries not a billionaire funded start-up (lookin’ at you Internet Archive!).
- Have an existing volunteer base. While there is a high probability that this project will be used for outreach with BHL users, it is prudent to engage with dedicated volunteers that are already interested in and experts at transcription and citizen science.
I did not require that tools support specific markup or encoding for a few reasons:
- Projects generally ask volunteers to either transcribe documents or pull out structured data from them. While we might like to ask for both, there does not seem to be a sustainable model for this quite yet.
- Part of BHL’s current workflow for mining scientific names requires plain text (.txt) files with no markup and there is a reasonable chance that this process will be enhanced to pull out dates, locations, and other value additions.
The four tools that I ended up spending some significant time with were Ben Brumfield’s FromThePage, the Australian Museum’s DigiVol, the Smithsonian Institution’s Transcription Center, and The Zooniverse’s Project Builder and their Scribe development framework. I should insert a disclaimer here: I am not starting completely from scratch with this research. MCZ has used both DigiVol and FromThePage for recent transcription projects, and everyone should go check out Science Gossip, the Missouri Botanical Garden’s Zooniverse project developed to generate keyword tags for illustrations ing BHL.
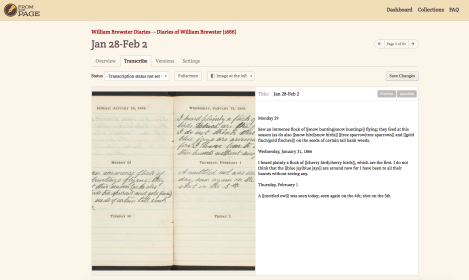
FromThePage
FromThePage, DigiVol, and the SI Transcription Center all operate in fundamentally similar ways, with each providing different features for libraries and volunteers. FromThePage is a lightweight, open source, collaborative transcription platform. It’s defining feature is its use of wiki style markup to link references and subjects within texts to dynamically index terms. The design is optimized for archives projects and is the simplest tool that can be deployed quickly. It has a very clean interface for viewing, transcribing, and coding people, places, and subjects across a collection of documents. While the markup system is simple, powerful, and effective, it does not fit seamlessly into the existing BHL metadata structure. FromThePage seems to have been developed specifically for archives collections that are not cataloged as libraries are. The wiki tagging could be designed specifically for BHL (and can be exported as TEI compliant XML), but would require a not insignificant amount of processing before uploading to the BHL portal.
DigiVol was built by the Australian Museum as an Atlas of Living Australia project and combines a similarly simple and attractive viewing and transcription interface with tools for extracting specimen data from items. There is not a
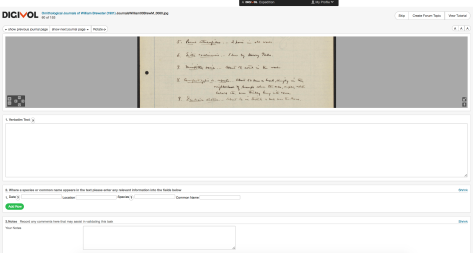
DigiVol
simple process for marking up text, but the platform features a form that invites volunteers to enter scientific names of specimen with dates and locations of their collection or observation. This generates a CSV document that retains valuable information in a structured format. DigiVol is a tremendous tool for BHL’s current functionality and architecture, but it does not have the flexibility to support other types of structured data or display markup.
The Smithsonian’s Transcription Center is perhaps the most successful of these tools that are designed for extracting full text transcriptions from archival collections.
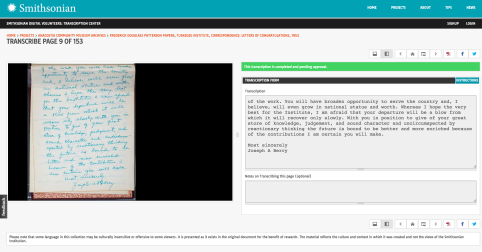
Enter a caption
The Transcription Center generates JSON files from text entered into a single data field. Volunteers can utilize a WYSIWYG-like toolbar that applies some TEI compliant markup but minimizes UI interference with the actual process of transcribing. The JSON-stored data allows any type of data to be stored in one database field instead of across several specific tables and can fairly easily interact with XML systems.
Jackpot!
Or, almost. Unfortunately, and perhaps understandably considering the strength of the system, the Transcription Center is not available outside of the Smithsonian’s network. While Smithsonian Institute Libraries is a member of BHL, the inclusion of projects outside the scope of SI may be a significant drawback to integrating fully with the Transcription Center.
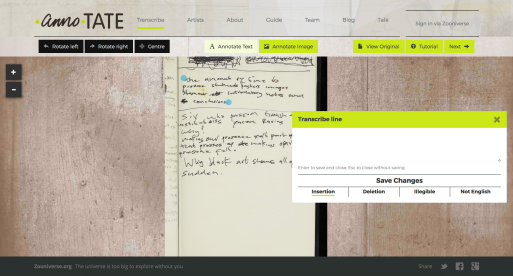
Anno.Tate
Finally, I discovered the Zooniverse. Originally designed for citizen scientists to extract structured data from extremely large data sets, the Zooniverse has recently embraced transcription and other humanities projects in its Scribe framework. Some of its recent forays include AnnoTate and Shakespeare’s World. The Zooniverse team has almost completely redesigned the model for a transcription platform with varying degrees of success. Instead of inviting volunteers to type complete page transcriptions into a text box, they break up the workflow into three types of tasks: Mark, Transcribe, and Verify. Users Mark where they see text on the page to maintain author’s explicit layout and formatting choices; a separate set of users Transcribe the text that was previously Marked, which preserves the relationship between pixels and text; and finally a third group reviews the Mark and Transcribe tasks for quality control. Output data can be harvested raw (from each task) or aggregated (from the whole set of Mark and Transcribe tasks for a given image) along with the level of Zooniverse’s confidence in the accuracy of the transcription. The output data is structured similarly to the Transcription Center’s (JSON), but is extracted as a CSV file, not via a RDBMS.
The Zooniverse relies on the concept of microtasking to break up labor intensive transcriptions that require high levels of intelligence and concentration.

From Victoria Van Hyning’s presentation at the Oxford Internet Institute
By splitting tasks into more manageable chunks with varying degrees of difficulty, citizen scientists can engage with the project at whatever level they desire. The idea relies on principles of gaming that ask for a shorter time commitments in order to encourage volunteers to return. Breaking up the tasks also improves the data quality by mitigating against user fatigue and boredom. While the Scribe framework is currently in beta and does not come without its snafus, the Zooniverse has recently been awarded an IMLS grant to build out its audio and text transcription tools in 2017-2018.
A final recommendation for a transcription tool will be largely informed by some of the choices that I and the other Residents propose for the future development of BHL. Will
the appropriate data (keywords, dates, locations, etc.) continue to be mined from the full-text transcriptions? Or could there be some significant benefits to asking volunteers to pull out that structured information from the images in addition to transcribing? It could be useful to quickly provide access to this data in structured formats, but conversely, establishing a workflow for mining the text will allow staff more flexibility in determining what facets to include and to triage digitized items’ value additions independently from their transcription.
This is a very general overview of some of what I’ve discovered about transcription tools in the last few weeks. If you are familiar with or have used any of these tools, please leave a comment or shoot me an email (kmika@fas.harvard.edu)! I am very interested in learning about both volunteers’ and libraries’ experiences with transcription projects.
Some resources that I found helpful:
FromThePage:
Ben Brumfield’s blog “Manusript Transcription” is a rich source for all types of discussions around transcribing documents. http://manuscripttranscription.blogspot.com/
“Crowdsourcing Transcription: FromThePage and Scripto.” The Chronicle of Higher Education, January 23, 2012. http://www.chronicle.com/blogs/profhacker/crowdsourcing-transcription-fromthepage-and-scripto/38028
DigiVol:
Stephens, Rhiannon. “The DigiVol Program.” AustralianMuseum.net, April 13, 2016. https://australianmuseum.net.au/the-digivol-program
Prater, Leonie. “DigiVol:Hub of Activity.” AustralianMuseum.net, December 17, 2013. https://australianmuseum.net.au/blogpost/museullaneous/digivolhub-of-activity
Smithsonian Institute Transcription Center:
The entire issue 12:2 of Collections: A Journal for Museums and Archives Professionals is dedicated to the Transcription Center, and each article presents several important perspectives to consider. https://journals.rowman.com/issues/1017503-collections-vol-12-n2
The Zooniverse:
Bowler, Sue. “Zooniverse Goes Mainstream.” A&G, 54:1, February 1, 2013. DOI: https://doi-org.ezp-prod1.hul.harvard.edu/10.1093/astrogeo/ats001
Kwak, Roberta. “Crowdsourcing for Shakespeare.” The New Yorker, January 16, 2017. http://www.newyorker.com/tech/elements/crowdsourcing-for-shakespeare
Van Hyning, Victoria. “Metadata Extraction and Full Text Transcription on the Zooniverse Platform.” Presentation to Linnean Society, October 10, 2016. https://www.youtube.com/watch?v=e-VeouLNmc0
Van Hyning, Victoria. “Humanities and Text-based Projects at Zooniverse.” Presentation to Oxford Internet Institute, February 16, 2016. https://www.youtube.com/watch?v=J4Oze3pSAK8
